Hello everyone,
We’re thrilled to announce two major extensions for canister HTTPS outcalls that significantly expand the power and flexibility of the Internet Computer. These have been some of the most requested features from the community, and we can’t wait to see what you build with them!
1. Connect to the Entire Web: IPv4 Support is Here! 
The wait is over! Canisters can now make HTTPS outcalls to services hosted on both IPv6 and IPv4 addresses.
How it Works
The system is designed to be fully automatic. For every outcall, the IC will first attempt a direct connection (ideal for IPv6). If that connection fails for any reason (like the server being IPv4-only), the request is automatically retried through a SOCKS proxy managed by the IC. You don’t need to change anything in your canister code; it just works. You can see more details here.
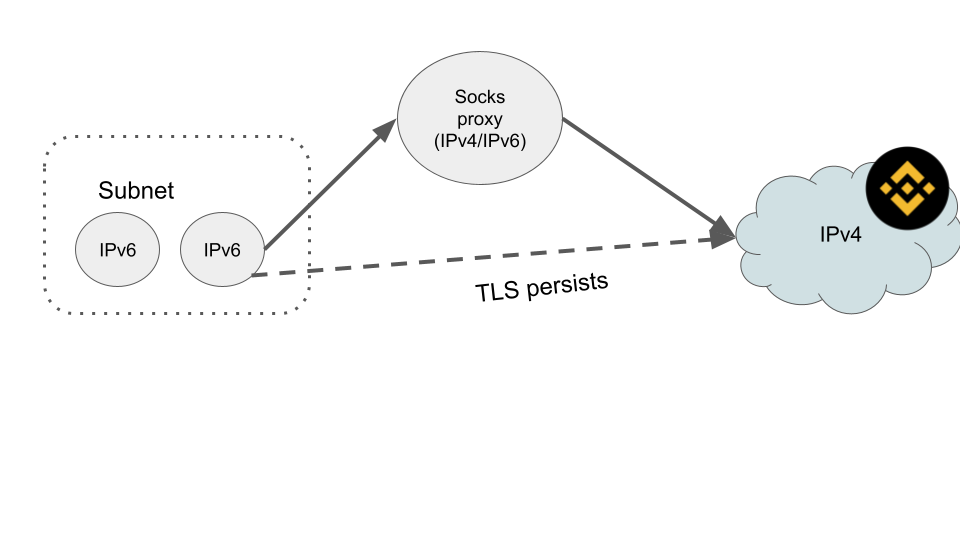
The TLS session is persisted end-to-end between the node and the destination server. This means the proxy only forwards the encrypted traffic, ensuring it never has access to the plaintext data and also cannot alter the server’s response. This guarantees both confidentiality and integrity.
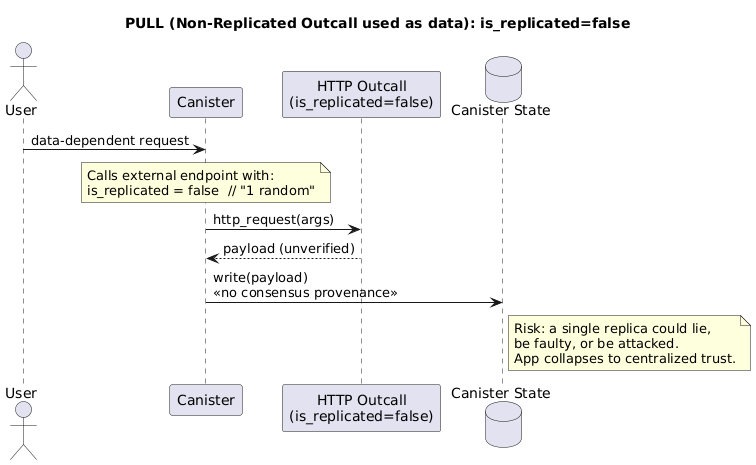
2. Experimental Non-Replicated Outcalls 
With the latest CDK (version 0.19.0-beta.1), you can now specify is_replicated = Some(false) in your http_request call. This ensures that only a single replica (chosen randomly for each request) will execute the request, instead of all of them.
You can check a working example in rust here:
let arg: HttpRequestArgs = HttpRequestArgs {
url: "https://www.random.org/integers/?num=1&min=1&max=1000000000&col=1&base=10&format=plain".to_string(),
max_response_bytes: None,
method: HttpMethod::GET,
headers: vec![],
body: None,
transform: None,
is_replicated: Some(false),
};
canister_http_outcall(&arg).await
And a Motoko example here:
let http_request : IC.http_request_args = {
url = url;
max_response_bytes = null;
headers = request_headers;
body = null;
method = #get;
transform = null;
is_replicated = ?false;
};
Why is this a game-changer?
This unlocks several new use cases that were previously difficult or impossible:
- Access Non-Idempotent Endpoints without triggering duplicate actions: Be able to e.g. request an email gateway to send an email, without it being sent N times, add certain resources with HTTP POST, call out to expensive endpoints etc.
- Interacting with Fast-Moving Data: Get a timely snapshot of rapidly changing data (e.g., a crypto price feed) without worrying about consensus failures from tiny differences between replica responses.
- Expensive API Calls: Drastically reduce costs by avoiding request amplification. If an API call is expensive, making it once instead of N times can be a huge saving.
The most important consideration is security: Since only one replica makes the call, the standard consensus guarantees do not apply. You must fully trust the single replica that handles your request, as a malicious or faulty replica could return an incorrect response. Only use this for interactions where you don’t need to trust the response data or can verify it by other means.
Additionally, its cycle price is the same as with fully replicated outcalls, and you could encounter latency issues. We are working on improving on those fronts.
Please Note: This feature is experimental and its interface may change based on feedback.
These new capabilities are now available for testing. We encourage you to upgrade your CDK or Motoko compiler to try them out and share your findings!
What’s Next on the Horizon 
These features are part of a broader effort to make canister outcalls more powerful, flexible, and affordable. Here’s a glimpse of what we’re focused on next:
- Cost of Outcalls: We are actively working on refining the pricing model to make all outcalls (especially those with a large
max_response_bytesparameter), more cost-effective. - Flexible Outcalls: We plan to give you more control over replication, such as the ability to request multiple responses from different replicas and resolve consensus directly in your canister logic.
Help Us Shape the Future: The API for Flexible Outcalls
As we look beyond the initial experimental non-replicated feature, our next goal is to build a truly Flexible Outcall API that gives developers the right balance between security and control. We are currently exploring two main directions and would love your feedback on which approach would be more valuable for your projects!
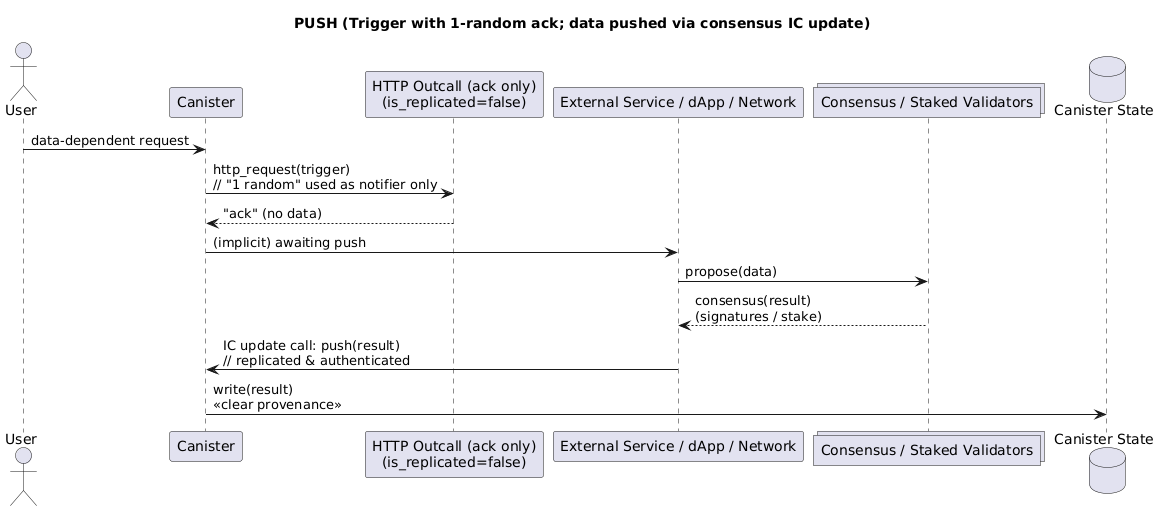
Path A: Simple & Secure: We could offer a straightforward flexible_http_request where all replicas in the subnet attempt the call, and your canister receives a list of at least 2f+1 responses. This is simple to use and provides a strong security guarantee—you know a majority of the responses come from honest replicas, making it easy to find a trustworthy median for price feeds or other dynamic data.
Path B: Advanced & Customizable: Alternatively, we could provide a more advanced API. This would allow you to specify “attempt the request on n random replicas and return after k responses” (k-of-n), or perhaps even target specific node IDs. This would give you more fine-grained control over the cost, latency, and trust trade-offs for your specific application.
With that context, we have a few key questions for the community:
- Looking at the two paths, which one feels more practical for your day-to-day work? Is the ‘Simple & Secure’ approach, where you get
2f+1responses and a guarantee of an honest majority, enough to solve most of your problems? Or do you have projects that would absolutely require the ‘Advanced & Customizable’k-of-nmodel? - If you’re excited about the ‘Advanced’ path, what’s a real-world problem you’re trying to solve where you’d need that level of
k-of-ncontrol? Your examples are the best way for us to know if this is a powerful ‘nice-to-have’ or a true ‘must-have’ for the community. - How do you view the trade-off of targeting specific
node_ids? Is the power to choose a specific node (a 100% trusted node for example) worth the added complexity of managing node identities yourself?