Boundary nodes throttling users access to query and update calls of canisters on subnet pjljw
Summary
An NFT project launched fully on 2021-09-01 20:00 UTC with earlier waves at 2021-09-01 16:00 UTC and 2021-09-01 19:00 UTC. The first wave at 16:00 UTC kicked off an increased volume of traffic to the subnet pjljw.

This traffic increased steadily and started to hit against the rate limits configured on the boundary nodes. The boundary nodes began limiting requests to canisters on the subnet. This caused impact to the project’s canister (responsible for the vast majority of the traffic):

As well as other canisters on the subnet.

The effective impact of this was that many users were unable to load applications on the webpage or interact with canisters as the majority of messages during this period of time were either rate limited or rejected by the replica. In the project’s case, many users were unable to load the application fully and claim their NFT.
During the peak period at 20:00 UTC, traffic increased dramatically, peaking at just over 38k requests/sec.

During earlier waves, the replicas and subnet behaved normally. During the peak period, an influx of heavy update traffic (202 call submit) came in going from 18 updates/s to over 1k updates/s to the subnet.

Close up for the critical time period:

This caused a dip in finalization rate from around 1 block/s to a bit over 0.3 blocks/s.

During this period, heavy ingress message throttling was observed, reaching levels of over 50 messages/s.

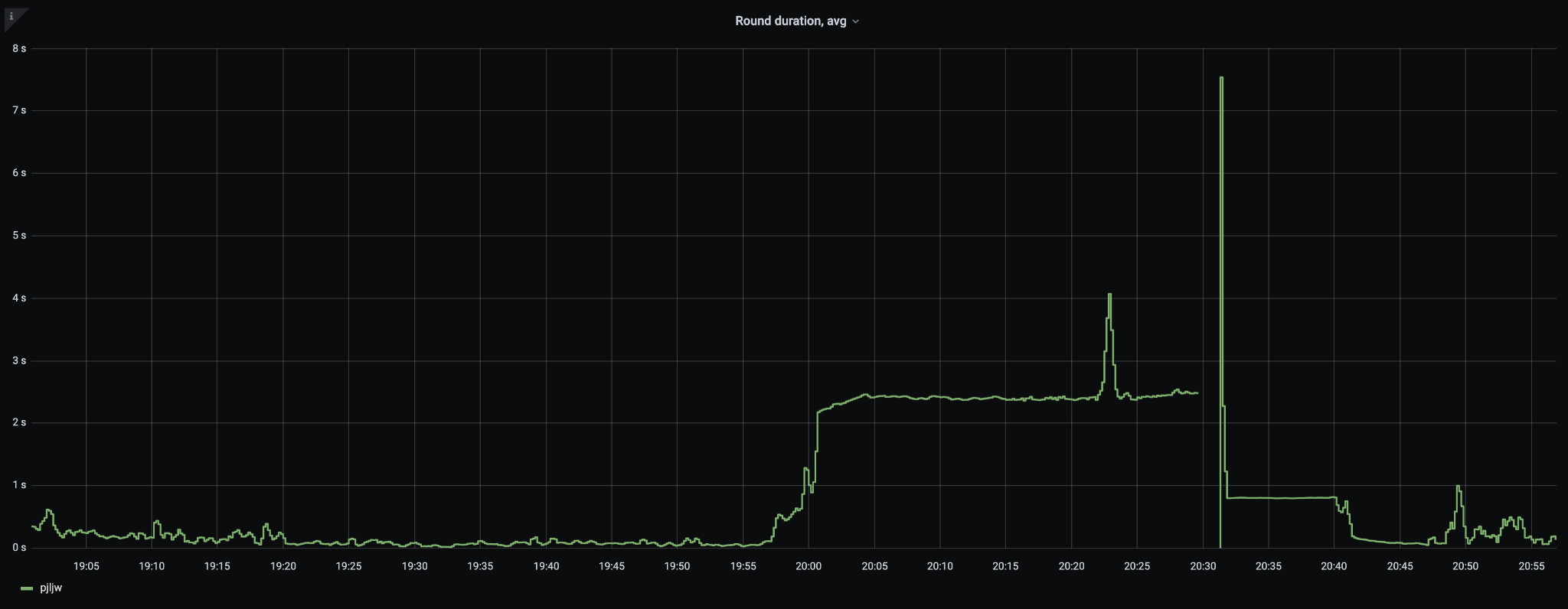
Execution round instruction went to over 1.8 billion and execution rounds were taking around 2.5 seconds (with large outliers).

During the peak period, client side (browser console log) visiting the project’s asset canister, directly served from the IC, shows a ton of error code 500 returned from boundary.ic0.app. Its frontend requires many assets to load to become fully functional: this explains why so many users were not able to do anything except keep reloading the page.
Timeline (UTC)
- 2021-09-01T16:00 - The first wave of NFT claiming and countdown starts.
- 2021-09-01T16:15 - Rate limiting by the boundary nodes is observed on query calls, a pattern which continues to increase as 20:00 approaches.
- 2021-09-01T19:00 - The second wave of NFT claiming occurs; this causes further increases in traffic, but update volume is still low as this group has a limited number of participants.
- 2021-09-01T20:00 - The main drop of NTFs occurs and traffic dramatically increases, peaking at 38k req/s to the boundary nodes. Subnet pjljw finalization rate drops to 0.3 blocks/s
- 2021-09-01T20:05 - The ICA dashboard is observed to fail to load during this period.
- 2021-09-01T20:40 - Traffic tapers off as the drop ends and project shows sold out. Traffic drops to 10k req/s and continues to drop as time goes on.
- 2021-09-01T20:45 - The ICA dashboard returns to normal operation.
- 2021-09-01T20:45 - Subnet pjljw returns back to normal finalization rate.
What caused the disruption?
High query load to a few canisters caused the rate limiting. The high update load caused the subnet performance to degrade afterwards. These two factors resulted in the project’s applications along with other canisters on the subnet being inaccessible to many users.
What went wrong?
The IC replicas were not serving real user traffic anywhere close to the theoretical maximum rate.
What went right?
The subnet pjljw continued processing queries and updates and did not fail despite the high traffic. The boundary nodes also continued successfully serving traffic. The rate limiting protections worked well and protected the subnet from the bulk of the traffic, which unfiltered could have caused more disruption in the subnetwork replicas.
Follow-up action Items
- Improve documentation on how to scale decentralized applications on the IC.
- Enable (standards compliant) caching of HTTP on the boundary nodes and communicate best practices to developers.
- Evaluate query API call result caching on replicas within a block interval.
- Use more threads for Execution (currently we are single threaded using 1 of 64 cores).
- Load test and tune the rate limits based on more realistic traffic loads.

