Summary
This post describes the DFINITY Foundation’s performance evaluation of the Internet Computer as of December 1, 2021,. We will periodically update the numbers to reflect performance improvements realized over time.
Scalability of the Internet Computer comes from partitioning the IC into subnet blockchains. Every subnet blockchain can process update calls from ingress messages independently from other subnets. The IC can scale up by adding more subnets at the cost of having more network traffic (as applications then need to potentially communicate across subnets). In its current form, the IC should be able to scale out to hundreds of subnets.
Query calls are read-only calls that are processed locally on each node. Scalability comes from adding more nodes, either to an existing subnet (at the cost of making consensus i.e. update calls more expensive) or as a new subnet.
The performance and load testing have been done primarily by @stefan-kaestle.
Test Setup
We are running all of our experiments concurrently against all subnets other than the NNS and some of the most utilized application subnets to avoid the disturbance of active IC users. We send load against those subnets directly and are not using boundary nodes for those experiments. Boundary nodes have additional rate-limiting which is currently set slightly more conservative compared to what the IC can handle and running against them therefore is unsuitable for performance evaluation. We are targeting all nodes in every subnet concurrently, much the same as what boundary nodes would be doing if we would use them.
We have installed one counter canister in every subnet. This counter canister is essentially a no-op canister. It only maintains a counter, which can be queried via a query call and incremented via update call. The counter value is not using orthogonal persistence, so the overhead for the execution layer of the IC is minimal. Stressing the counter canister can be seen as a way to determine the system overhead or baseline performance.
Since nodes and subnets are being constantly added to the IC, it is worth describing the topology during these tests:
- Nodes - 375
- Subnets - 27
- Largest subnet - 37 nodes
- Smallest subnet - 13 nodes
Source: IC Dashboard
Measurements
Update calls
The Internet Computer’s (currently at 26 subnets + the NNS subnet) can currently sustain more than 11’000 updates/second for a period of four minutes, with peaks over 11’500 updates/second.
The update calls we have been measuring here are triggered from Ingress messages sent from outside the IC.
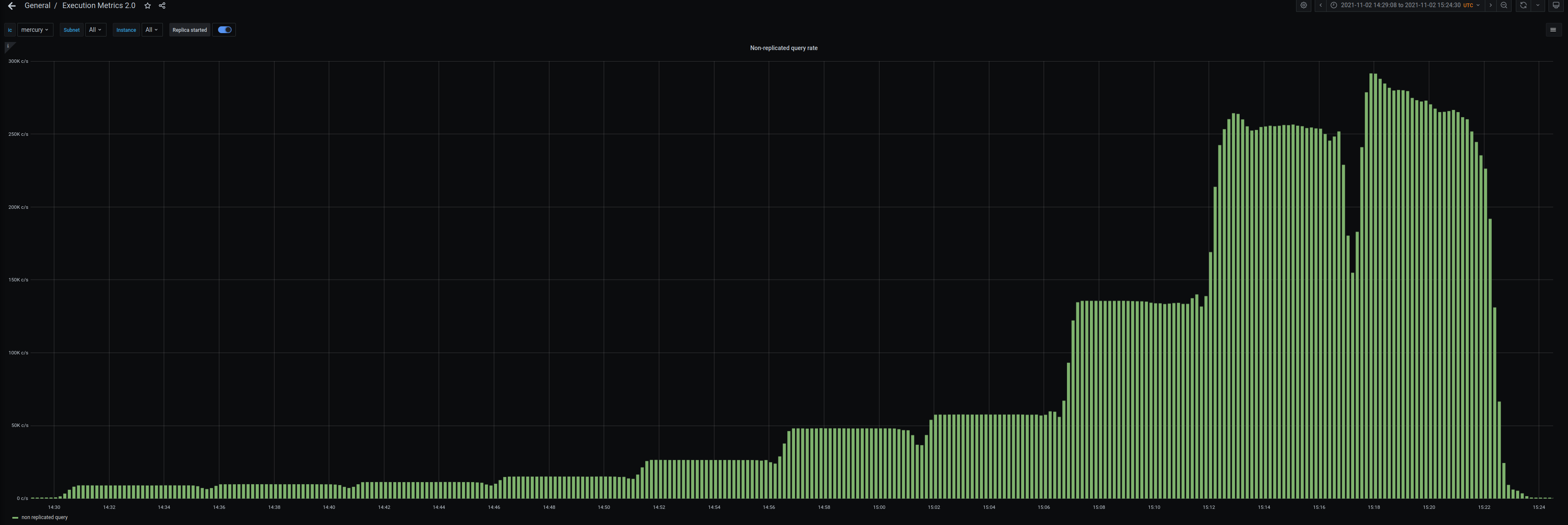
Query calls
Arguably more important are query calls, since they contribute to more than 90% of the traffic on the IC.
The Internet Computer can currently process up to 250’000 queries per second. During our experiments, we increment the load incrementally and run each load for a period of 5 minutes.
Conclusion and next steps
The Internet Computer today already shows impressive performance. On top of that, it should be possible to further scale out the IC by:
- More subnets: This will immediately increase the query and update throughput. While adding subnets might eventually lead to other scalability problems, the IC in its current shape should be able to support hundreds of subnets.
- Performance improvements: Performance can also be improved by a better single machine, network, and consensus performance tuning. Increasing the performance by at least an order of magnitude should be possible.