Good luck. But this is ironic the cicp has the same design issues that you and anvil complained about with wtn. The only difference is you control this one.
Wtn devs have never lied. Hopefully you and anvil actually create a solution that fixes the issues that started all the drama.
Interesting thread. May I clarify a few things, @infu?
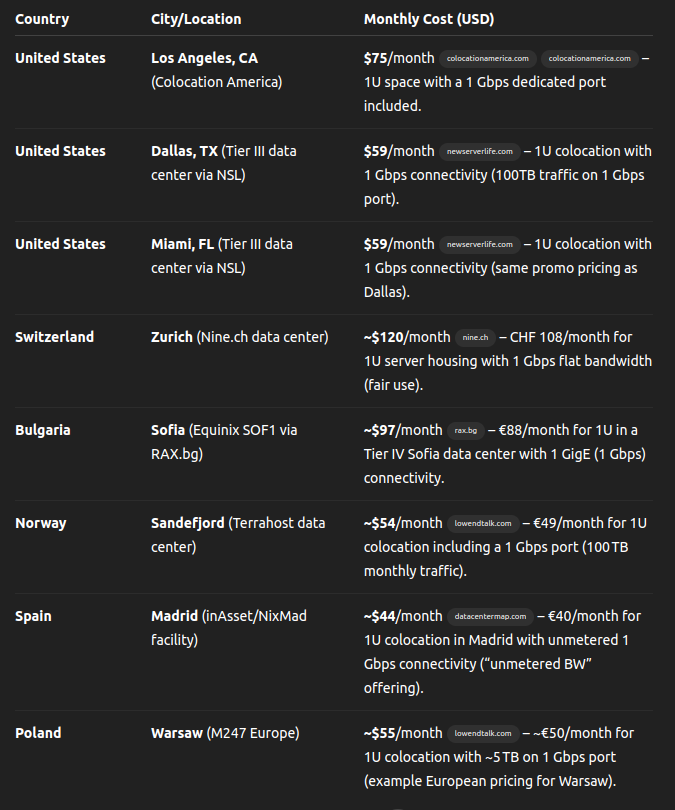
The price of colocation for a 1U server with unlimited 1 Gbit/s bandwidth varies significantly around the world, reaching $400 in some countries. How are you going to address the discrepancy in pricing?
Who is going to be the legal owner of the servers?
What are the terms of giving the servers to the operators? Are operators leasing them? Are they hired contractors to look after them? Who are they leasing it from (in the former scenario) or signing a contract with (in the latter)?
What is your plan in case the node operator goes away with the node once you give it to them?
Who is going to own contracts with DC (typically signed for a year upfront)? In some places, DC won’t accept servers that aren’t owned by the entity that brings them in or do not have active warranty coverage. Do you have a plan for such occasions?
Who is going to do the maintenance and troubleshooting of the servers when they misbehave? The price of remote data centre workers varies from $100 to $400 per hour, and they need super-precise instructions on where to go, what to press, what to pull, etc. In some cases, your DC contract may include a certain number of remote hands and eyes hours per month, but this is usually the case when you rent space for multiple servers, not just one.
If you are ready to maintain the node remotely, you need a way to access BMC, which requires additional hardware to be installed, configured, and maintained.
Who is going to have the authority to let server support engineers from the manufacturers go into the DC and replace faulty server components?
As a side note, we strive to make it as easy as possible for node providers to do their jobs, but it is far from being as easy as self-maintaining IC-OS nodes, no matter how much we would like it to be.
As our future NP, you’ll get to know the joy of working with remote hands and eyes that rarely (if ever) pull the correct wire or HDD caddy even with precise instructions on the first try
I am sure, there are places that will cost 400$, if someone looks harder, they can even find places that cost 800$ Like a datacenter on top of Burj Khalifa.
I had to send a few emails to the best server hardware manufacturer nearby. They helped me pick the best components. Then tested them for 48 hours and sent them directly to the T3 datacenter (A company FB and Google use for their regional servers). The technicians plugged them, and all I had to do was connect to the servers through IPMI and install the OS. We visited the datacenter once and took pictures with the servers, but that was not really required. I haven’t seen the servers ever since. They didn’t stop working, and nothing broke yet. I think most of them didn’t require a restart for the last 3.5 (1305 days) years.
In the event of a software problem, remote IPMI will let me fix things. If a power supply or something similar stops working, I can send an email to the datacenter, for them to send the broken server to the hardware manufacturer, where it gets fixed and sent back. I was told it’s a standard procedure, but it hasn’t happened yet for 7y with 4 servers.
Just to be clear, I am not offering to run all IC nodes through Neutrinite. We just need 1 per ~150k ICP, around 2% goes for nodes to keep a 1:1 ratio. Different LLCs can own the servers same way RWAs work and mint NFTs for them, which the DAO holds. The DAO gets all the ICP rewards directly, while the service provider gets ~300$ in NTN. I’ll be happy to support the IC and run some servers to see what the process is and what the obstacles are. With 10 servers, cICP can go up to 1,500,000 ICP, which is pretty much the total amount of ICP in DEXes right now. Once everything has been done at least once and works well, we can scale a few times.
Anything Infu does, I support. He’s been around for a while, he knows what he’s doing and he’s got the best interest in the long-term success of the ecosystem.
I like to learn more about how cICP works from a non-technical point of view, so investors can understand better what’s the unique value proposition.
It’s just that 1444 nodes run on defective hardware. Now that we figured it out, the NNS can divert funds away from 400$/h remote hands in need of instructions to plug cables and into the hands of PhDs, development, and DeFi.
Constructive contributions please. It’s clear that a large amount of hard work has gone into cICP. Much of this thread is important. You’re intentionally stirring the pot. Please don’t