I for one would very much welcome something like that, especially if coming from the community! I don’t speak for the entire Foundation though. But I don’t expect opposition. Especially if it can be integrated with the rest of the tooling and, even better, be used to submit proposals.
Probably even better and easier to start using - would be to adjust the existing tooling. I would be happy to have external contributions there.
3 Likes
@Lorimer @wpb, to clarify, the target topology is as @wpb indicates the topology that should be worked towards, in that it is the topology intended to be achieved in the next half to one year. This was also stated when the first proposal was submitted for voting.
The target topology has been used as basis for the optimization tool that was used to determine how many Gen2 node machines were required, taking into account the decentralization coefficients. You can find further discussion on these topic here. The optimization tooling is open source and the community has also contributed to that. Note that the optimization tooling is a python module, and is different from the dre “health” tooling that is weekly run for node replacements; but both calculate the same Nakamoto coefficients.
When mentioning that the limiting factor for decentralization is the country coefficient and the number of Gen2 spare nodes, and that spare nodes are not included in the optimization tooling, this does not mean - as @lorimer assumed - that there are not enough Gen2 nodes, so the conclusion that community was asleep or that target topology is unachievable is not correct:
- There are approximately (not taking into account dead nodes or nodes in maintance) 361 Gen2 Nodes, whereas the target topology requires a minimum of 136 Gen2 nodes (based on the number of nodes in SEV subnets). The difference between these two numbers can be explained by (1). the target decentralization coefficients required more nodes in new countries, with new node providers, and in new data centers, also for the subnets that are not SEV subnets (2). several new node providers had ordered node machines before the optimization tooling was introduced and voted upon, so these already ordered nodes (the so called “node pipeline”) were agreed by the community to be added to the IC network as well.
- If you run the optimization tool while removing 20 Gen2 nodes, the target topology can still be achieved, even with Fiduciary subnet size and II subnet size increased to 34. See also the outcome below. Feel free to run this yourself.
- The tooling is using linear optimization, and you can actually see the outcome per node per subnet per node provider, as proof that this optimization can be achieved.
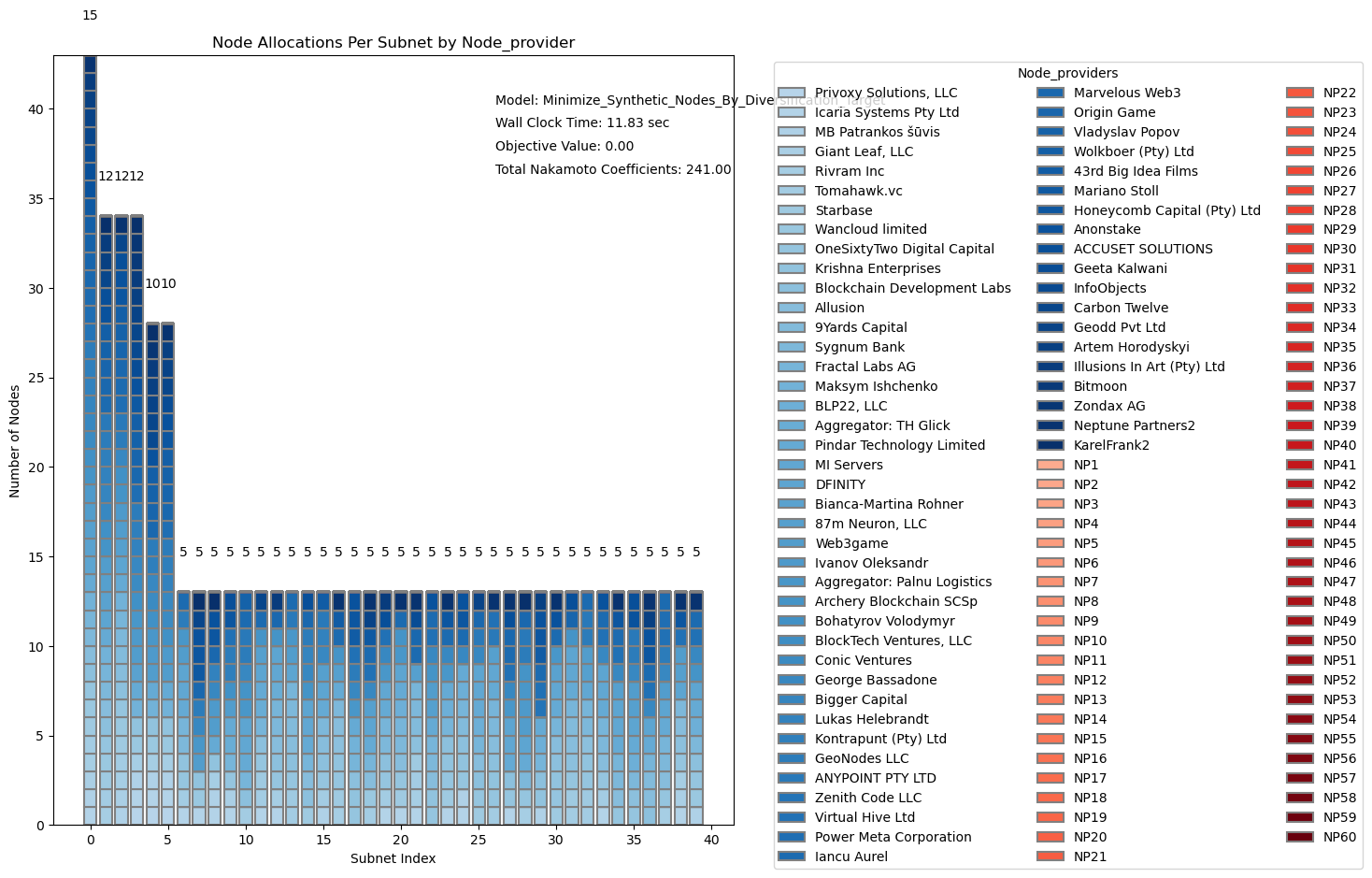
Since the optimization tooling is stand alone and not integrated in the NNS, as @wpb rightly states executing all subnet proposals to achieve this topology in practice is quite complex and time consuming, and any suggestions are welcome in that respect. The intention is to incrementally achieve this through the individual subnet proposals that the DRE is submitting every week. But other ideas are very much welcome.
In conclusion, @sat @lorimer @wpb as the new target topology can be achieved with the available nodes, I do not see a reason for rejecting the motion proposal.
3 Likes
Thanks @SvenF, this response is very much appreciated ![]()
Please note that it would’ve been useful to have had this discussion prior to the motion proposal having been submitted (I highlighted concerns 3 days prior to the submission of this motion proposal). Instead there is now little more than a day left in the voting period.
I still see significant inconsistencies in the communication around this proposal. Empirical observation from DRE team is that there are rarely enough nodes to meet the current target for all subnets (based on their tooling).
I’ve run the python optimisation tooling before and inspected the results, but I haven’t had time to review the algorithm being used to collect this evidence (which is in contrast to empirical evidence). It really must be emphasised that the NNS subnet (the most security-critical one) currently has:
- 8 nodes in the same country (instead of the achievable target of 3)
- 2 nodes in the same data center (instead of the achievable target of 1)
- 3 nodes with the same owner (instead of the achievable target of 1)
- 2 nodes from the same node provider (instead of the achievable target of 1)
It should be reiterated that the NNS isn’t the only subnet with these significant problems.
You’re asking the community to place a lot of faith in the results of a python tool that has produced results that are very much at odds with the current situation (regarding the existing IC Topology Target). My experience is that tooling bugs are extremely common.
I’m planning to review the python code when I get a chance, but in the meantime could you please confirm that when calculating the availability of spare nodes, the python tooling is taking into account every single dimension at once (instead of each dimension individually)? i.e. it means very little that there are n number of nodes in c number of countries if the other constraints that must be adhered to simultaneously would be violated by the necessary subnet allocations.
Again, I really appreciate your response ![]() , I just wish the community had had it sooner relative to the submission of this motion.
, I just wish the community had had it sooner relative to the submission of this motion.
1 Like
Thanks @lorimer and it would be nice to see your suggestions on how to improve the optimization tooling. For the spare nodes, since one does not know in advance which node machines might fail in which country, and how many, it is difficult to calculate how many spare nodes are needed and where these need to be located. Hence an high level estimate was used as estimate for the number of spare nodes needed.
1 Like
Thanks @SvenF, I’ll do some planning/prototyping and maybe put a grant application together if it seems warranted based on the amount of work required.
Regarding the ‘estimate’ that there are enough spare nodes for the existing (and proposed, more stringent) topology, this clearly is not taking into account real world factors (and sounds like it’s not considering all constraints simultaneously, given your response). I think this explains how the IC topology is in the state that it’s currently in.
I think it would be misguided to accept this proposal, given the context, misleading statements (i.e. ‘Given that the IC network currently has sufficient spare node machines, no additional node providers or node machines need to be onboarded’), and given the unanswered questions regarding what is achievable (which nobody currently has an answer for).
Not sure where you got these numbers. The current state is that US has 7 nodes, and https://dashboard.internetcomputer.org/proposal/132179 brings this number further down to 6. Future proposals will bring it further down, towards the target topology.
I feel it’s unnecessarily harsh to say that things are falling apart if the Nakamoto coefficient for the country is 4 and increasing to 5 in the new proposal.
Note that the currently adopted target topology sets the objective for the NNS subnet to 3 nodes per country. That number strictly gives us the Nakamoto Coefficient of 5. We are already getting there with the new proposal. There is no need for a drama.
You’re right, the current US number is 7 (the other numbers are correct). It’s possible I confused a nearby Canadian node for a US node when I wrote that post.
Subnet characteristic limits give subtly different assurances than a Nakamoto coefficient. These are related but different concepts, and the IC target topology has been intentionally specified in terms of characteristic limits.
Please don’t trivialise the valid concerns I’m raising as unnecessary drama. There’s an obvious mismatch between the targets that are being planned by the community and the targets that are actually being optimised for. This needs resolving, and I’d suggest a new motion proposal to clarify matters.
I just submitted the first proposal from the series of proposals we should submit related to this activity:
3 Likes
And I just submitted another proposal that increases the size of the Internet Identity (uzr34) subnet:
4 Likes
Voted to adopt proposal 133071.
This proposal adds 3 new nodes to subnet uzr34, given that this subnet currently has 28 nodes and the target number of nodes was recently increased to 34 in the updated target topology. As seen in the proposal (which I verified using the DRE tool), the overall effect of these additions is to increase the log average Nakamoto coefficient while still keeping the number of nodes per node provider, data centre, data centre owner and country within the limits specified in the target topology.
3 Likes
Thanks @timk11! Did you mean increase? (No worries, I make such typos all the time)
Overall replacement impact: (gets better) the average log2 of Nakamoto Coefficients across all features increases from 2.8121 to 2.8370
2 Likes
Whoops! I did indeed. Thanks for catching that. I’ve edited it in the original post. ![]()
3 Likes
I’ve posted a review that’s relevant to the motion proposal that this forum topic is about →
![]() This relates to my comment above…
This relates to my comment above…
I’ve yet to review the new proposal for the II subnet (I’m having to squeeze in time where I can find it).
Update: Reviewed it and that particular proposal looks good ![]()
3 Likes
Voted to adopt. Subnet Management - uzr34 (II) - #41 by ZackDS .
3 Likes
Voted to adopt proposal 133071.
The proposal adds three new nodes to the uzr34 subnet (Internet Identity). The target number of nodes for this subnet is 34 as seen in the Target Topology. Using the Dre tool is also possible to verify that it does indeed increase the average log2 of Nakamoto Coefficients across all features as stated in the proposal.
1 Like
Here’s an update with where I’ve got with this so far. I initially intended to take a look at writing a stochastic optimisation procedure for the IC Target Topology problem, but there are actually pre-existing tools that do a great job of this sort of thing.
Allocating nodes to subnets is sort of like a table seating allocation problem (constraints about who can be at each table, given who is already at that table, is similar in nature to which nodes can join a subnet)

Screenshot from MiniZinc’s promotional material.
I’ve been chipping away at a comprehensive script to see if MiniZinc is capable of modelling all the things that the IC Target Topology problem needs to have modelled. So far I haven’t come up against any blockers.
Here's a working MiniZinc script that I've been developing (click to expand)
Note that the script is initialised with toy data at the moment (not real IC node/subnet data/constraints), i.e. just a few mock nodes and subnets, with a very limited set of characteristic options to choose from (e.g. just two continents defined)
Documentation is here to explain the way that MiniZinc scripts are formatted (lots of arrays and integers for the sake of performance). ChatGPT-4o also appears to do a fairly good job of describing what a script is doing and what the syntax means (useful for quickly getting familiar with the language).
% Define the enums for different characteristics
enum Continent = {Europe, America};
enum Country = {US, Spain, France};
enum ISP = {Virgin, O2, BT};
enum City = {Barcelona, Washington, Paris};
enum DataCenter = {DC1, DC2, DC3};
enum Owner = {Alex, Pippa, Edward};
enum NodeProvider = {Melissa, James};
% Define the number of nodes
int: num_nodes = 6;
% Define the constraint weights
int: highest_priority_weight = 1000000000;
int: higher_priority_weight = 1000000;
int: high_priority_weight = 10000;
int: medium_priority_weight = 1000;
int: low_priority_weight = 100;
int: lowest_priority_weight = 1;
% Define the characteristics for each node
array[1..num_nodes] of Continent: node_continent = [America, America, Europe, Europe, Europe, Europe];
array[1..num_nodes] of Country: node_country = [US, US, Spain, France, France, France];
array[1..num_nodes] of ISP: node_ISP = [Virgin, O2, BT, Virgin, O2, BT];
array[1..num_nodes] of City: node_city = [Washington, Washington, Barcelona, Paris, Paris, Paris];
array[1..num_nodes] of DataCenter: node_data_center = [DC1, DC2, DC3, DC3, DC3, DC3];
array[1..num_nodes] of Owner: node_owner = [Alex, Pippa, Edward, Pippa, Pippa, Pippa];
array[1..num_nodes] of NodeProvider: node_provider = [Melissa, Melissa, James, James, James, Melissa];
% Define the x, y locations for each node
array[1..num_nodes] of int: node_x = [1, 5, 2, 8, 3, 7]; % lng rounded to int
array[1..num_nodes] of int: node_y = [1, 2, 5, 6, 3, 4]; % lat rounded to int
% Define the number of subnets (+ unassigned nodes as their own group) and their sizes
int: num_groups = 3;
array[1..2] of int: subnet_size = [3, 2];
int: unassigned_group = 3; % third group isn't a subnet, it's the group of unassigned nodes
% Define the starting state (initial node assignments to subnets)
array[1..num_nodes] of int: initial_assignment = [1, 1, 2, 2, 3, 3];
% Define the priority (weight) for each subnet
array[1..2] of int: subnet_priority = [2, 1]; % Subnet 1 is more important than Subnet 2
% Define which nodes are in a good state (true = good, false = bad)
array[1..num_nodes] of bool: is_good_node = [true, false, true, false, true, true];
% Define which nodes support SEV (true = supports SEV, false = does not support SEV)
array[1..num_nodes] of bool: supports_SEV = [true, false, true, true, false, true];
% SEV constraints for subnets
% Define which subnets require all nodes to support SEV (true = SEV required, false = SEV not required)
array[1..2] of bool: SEV_required = [true, false];
% Define the decision variables (node assignments to subnets)
array[1..num_nodes] of var 1..num_groups: node_assignment;
% Calculate the number of swaps required from the initial state
array[1..num_nodes] of var 0..1: swap_required;
constraint
forall(n in 1..num_nodes) (
swap_required[n] = bool2int(node_assignment[n] != initial_assignment[n])
);
% Ensure that the first two subnets contain the exact required number of nodes
constraint
forall(s in 1..2) (
sum([bool2int(node_assignment[n] == s) | n in 1..num_nodes]) == subnet_size[s]
);
% Ensure that the unassigned group can have between 0 and all nodes, i.e., between 0 and 6 nodes
constraint
sum([bool2int(node_assignment[n] == unassigned_group) | n in 1..num_nodes]) <= num_nodes;
% Ensure bad nodes do not reside in the first two node groups (the subnets, as opposed to the unassigned group)
array[1..2] of var int: bad_node_violations;
constraint
forall(s in 1..2) (
bad_node_violations[s] = sum([bool2int(node_assignment[n] == s /\ not is_good_node[n]) | n in 1..num_nodes])
);
% Violations for SEV requirements
array[1..2] of var int: SEV_violations;
constraint
forall(s in 1..2) (
SEV_violations[s] =
sum([bool2int(node_assignment[n] == s /\ not supports_SEV[n]) | n in 1..num_nodes]) * bool2int(SEV_required[s])
);
% Preference for non-SEV nodes in subnets that do not require SEV
array[1..2] of var int: non_SEV_preference_violations;
constraint
forall(s in 1..2) (
non_SEV_preference_violations[s] =
sum([bool2int(node_assignment[n] == s /\ supports_SEV[n]) | n in 1..num_nodes]) * bool2int(not SEV_required[s])
);
% Define violation variables for the first two subnets
array[1..2] of var int: continent_violations;
array[1..2] of var int: country_violations;
array[1..2] of var int: ISP_violations;
array[1..2] of var int: city_violations;
array[1..2] of var int: datacenter_violations;
array[1..2] of var int: owner_violations;
array[1..2] of var int: provider_violations;
% Max allowable repeats for characteristics in the first two subnets
array[1..2] of int: max_continent_repeats = [1, 1];
array[1..2] of int: max_country_repeats = [1, 1];
array[1..2] of int: max_ISP_repeats = [1, 1];
array[1..2] of int: max_city_repeats = [1, 1];
array[1..2] of int: max_datacenter_repeats = [1, 1];
array[1..2] of int: max_owner_repeats = [1, 1];
array[1..2] of int: max_provider_repeats = [1, 1];
% Correctly compute the violation counts, weighted by subnet priority
constraint
forall(s in 1..2) (
continent_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_continent[n] == c) | n in 1..num_nodes]) - max_continent_repeats[s]) | c in Continent]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
country_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_country[n] == c) | n in 1..num_nodes]) - max_country_repeats[s]) | c in Country]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
ISP_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_ISP[n] == c) | n in 1..num_nodes]) - max_ISP_repeats[s]) | c in ISP]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
city_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_city[n] == c) | n in 1..num_nodes]) - max_city_repeats[s]) | c in City]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
datacenter_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_data_center[n] == dc) | n in 1..num_nodes]) - max_datacenter_repeats[s]) | dc in DataCenter]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
owner_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_owner[n] == o) | n in 1..num_nodes]) - max_owner_repeats[s]) | o in Owner]) * subnet_priority[s]
);
constraint
forall(s in 1..2) (
provider_violations[s] =
sum([max(0, sum([bool2int(node_assignment[n] == s /\ node_provider[n] == np) | n in 1..num_nodes]) - max_provider_repeats[s]) | np in NodeProvider]) * subnet_priority[s]
);
% Distance calculation: Sum of pairwise distances within the same subnet
function var int: wrap_around_distance(int: _diff, int: max_val) =
min(_diff, max_val - _diff);
% Manhattan distance (no floating-point operations), also not worth taking globe curvature into account
function var int: pairwise_distance(int: n1, int: n2) =
let {
var int: dx = wrap_around_distance(abs(node_x[n1] - node_x[n2]), 360),
var int: dy = wrap_around_distance(abs(node_y[n1] - node_y[n2]), 180)
} in
dx + dy;
% Calculate the total distance for each subnet and the number of pairs
array[1..2] of var int: total_distance;
array[1..2] of var int: num_pairs;
constraint
forall(s in 1..2) (
num_pairs[s] = sum([bool2int(n1 != n2 /\ node_assignment[n1] == s /\ node_assignment[n2] == s) | n1, n2 in 1..num_nodes]) div 2
);
constraint
forall(s in 1..2) (
total_distance[s] =
sum([pairwise_distance(n1, n2)
| n1 in 1..num_nodes, n2 in 1..num_nodes
where n1 != n2 /\ node_assignment[n1] == s /\ node_assignment[n2] == s])
);
% Calculate the average distance for each subnet, avoid division by zero
array[1..2] of var int: average_distance;
constraint
forall(s in 1..2) (
average_distance[s] =
(if num_pairs[s] > 0 then total_distance[s] div num_pairs[s] else 0 endif)
);
% Count violations based on their priority level
var int: highest_priority_violations =
sum(bad_node_violations) + sum(SEV_violations);
var int: higher_priority_violations =
sum(country_violations) + sum(datacenter_violations) + sum(owner_violations) + sum(provider_violations);
var int: high_priority_violations =
sum(swap_required);
var int: medium_priority_violations =
sum(continent_violations) + sum(ISP_violations) + sum(city_violations);
var int: low_priority_violations =
sum(non_SEV_preference_violations);
% Objective: Minimize the total number of violations while maximising average distance
solve maximize
-(
highest_priority_violations * highest_priority_weight +
higher_priority_violations * higher_priority_weight +
high_priority_violations * high_priority_weight +
medium_priority_violations * medium_priority_weight +
low_priority_violations * low_priority_weight
)
+ sum(average_distance) * lowest_priority_weight;
% Output the node assignments, violations, and counts for different priority levels
output [
"Node assignments:\n",
show(node_assignment),
"\nContinent violations: ", show(continent_violations),
"\nCountry violations: ", show(country_violations),
"\nISP violations: ", show(ISP_violations),
"\nCity violations: ", show(city_violations),
"\nData center violations: ", show(datacenter_violations),
"\nOwner violations: ", show(owner_violations),
"\nProvider violations: ", show(provider_violations),
"\nBad node violations: ", show(bad_node_violations),
"\nSEV violations: ", show(SEV_violations),
"\nNon-SEV preference violations: ", show(non_SEV_preference_violations),
"\nNumber of swaps required: ", show(sum(swap_required)),
"\n - Highest Priority Violations: ", show(highest_priority_violations),
"\n - Higher Priority Violations: ", show(higher_priority_violations),
"\n - High Priority Violations: ", show(high_priority_violations),
"\n - Medium Priority Violations: ", show(medium_priority_violations),
"\n - Low Priority Violations: ", show(low_priority_violations),
"\n - Average distances: ", show(average_distance),
"\n"
];
Here's the output you currently get (click to expand)
Note that multiple solutions are provided in the output (separated by ----------). The solutions are improved iteratively (worst solutions provided first, followed by better and better ones). Node assignments are expressed by providing a number that represents a subnet for each node. There are only 6 nodes in total in this toy example, and 2 subnets (number 3 represents unassigned nodes). Violations for each subnet are expressed as a count (1 for each of the two subnets). These violations are then considered in terms of their severity (defined by weightings in the script).
Note that a perfect solution would have 0 violations (there’s no perfect solution in this example script). Also node that the script seeks to maximise average distance between nodes (as a very low priority optimisation), while first seeking to minimize the number of constraint violations.
Node assignments:
[1, 2, 2, 3, 1, 1]
Continent violations: [2, 0]
Country violations: [2, 0]
ISP violations: [0, 0]
City violations: [2, 0]
Data center violations: [2, 0]
Owner violations: [2, 0]
Provider violations: [2, 0]
Bad node violations: [0, 1]
SEV violations: [1, 0]
Non-SEV preference violations: [0, 1]
Number of swaps required: 4
- Highest Priority Violations: 2
- Higher Priority Violations: 8
- High Priority Violations: 4
- Medium Priority Violations: 4
- Low Priority Violations: 1
- Average distances: [12, 12]
----------
Node assignments:
[3, 2, 2, 1, 1, 1]
Continent violations: [4, 0]
Country violations: [4, 0]
ISP violations: [0, 0]
City violations: [4, 0]
Data center violations: [4, 0]
Owner violations: [4, 0]
Provider violations: [2, 0]
Bad node violations: [1, 1]
SEV violations: [1, 0]
Non-SEV preference violations: [0, 1]
Number of swaps required: 5
- Highest Priority Violations: 3
- Higher Priority Violations: 14
- High Priority Violations: 5
- Medium Priority Violations: 8
- Low Priority Violations: 1
- Average distances: [10, 12]
----------
Node assignments:
[2, 1, 2, 3, 1, 1]
Continent violations: [2, 0]
Country violations: [2, 0]
ISP violations: [2, 0]
City violations: [2, 0]
Data center violations: [2, 0]
Owner violations: [4, 0]
Provider violations: [2, 0]
Bad node violations: [1, 0]
SEV violations: [2, 0]
Non-SEV preference violations: [0, 2]
Number of swaps required: 4
- Highest Priority Violations: 3
- Higher Priority Violations: 10
- High Priority Violations: 4
- Medium Priority Violations: 6
- Low Priority Violations: 2
- Average distances: [8, 10]
----------
Node assignments:
[2, 1, 3, 2, 1, 1]
Continent violations: [2, 0]
Country violations: [2, 0]
ISP violations: [2, 1]
City violations: [2, 0]
Data center violations: [2, 0]
Owner violations: [4, 0]
Provider violations: [2, 0]
Bad node violations: [1, 1]
SEV violations: [2, 0]
Non-SEV preference violations: [0, 2]
Number of swaps required: 4
- Highest Priority Violations: 4
- Higher Priority Violations: 10
- High Priority Violations: 4
- Medium Priority Violations: 7
- Low Priority Violations: 2
- Average distances: [8, 24]
----------
Node assignments:
[2, 1, 1, 2, 1, 3]
Continent violations: [2, 0]
Country violations: [0, 0]
ISP violations: [2, 1]
City violations: [0, 0]
Data center violations: [2, 0]
Owner violations: [2, 0]
Provider violations: [2, 0]
Bad node violations: [1, 1]
SEV violations: [2, 0]
Non-SEV preference violations: [0, 2]
Number of swaps required: 3
- Highest Priority Violations: 4
- Higher Priority Violations: 6
- High Priority Violations: 3
- Medium Priority Violations: 5
- Low Priority Violations: 2
- Average distances: [8, 24]
----------
==========
Finished in 257msec.
![]() The final solution means the first node should belong to subnet 2, second node should belong to 1, same as the next node, next node should belong to subnet 2, then subnet 1, and the last node is best to be unassigned (there are only 2 subnets modelled in this example, so 3 means unassigned).
The final solution means the first node should belong to subnet 2, second node should belong to 1, same as the next node, next node should belong to subnet 2, then subnet 1, and the last node is best to be unassigned (there are only 2 subnets modelled in this example, so 3 means unassigned).
I may not have time to progress this for a bit, so I thought it would be good to share my progress with the community in case anyone would like to pick it up and make further progress or take it in another direction.
Hopefully the comments make sense (you can always ask if not). I’ve simplified this script where I can (such as using toy node/subnet data for the moment), as a simple demonstration.
You can run the script by pasting it into the MiniZinc playground or by downloading the tool and running it locally.
Things that still need doing with the above script:
- Instead of using a very restricted set of toy data, initialise the script with real node data, and real subnet definitions (in terms of constraints).
- When a large number of nodes and subnets are considered it’s likely that performance blockers will be hit due to the problem currently being framed as a minimization problem. Performance could almost certainly be significantly improved by framing this purely as a constraint satisfaction problem (if a solution doesn’t meet the constraints exactly it gets chucked away, eagerly pruning the search space). The downside of this is that the output of the script would be less descriptive, and if the constraints can’t be solved perfectly, no solution will be provided at all (this would still be useful for determining if the IC Target Topology is actually achievable).
- The script considers nodes that belong to other subnets (not just the unassigned nodes), and tries to find a globally optimal solution with a minimal number of node swaps from a starting state (defined in the script). Related discussion here (point 2). For practical purposes, the script may need tweaking to prefer unassigned nodes, and/or to constrain the problem to a specific subnet or set of subnets.
- Needs integrating with a tool that automates proposal submission (ideally after checking the proposed solution with existing tooling / approaches). Maybe this sort of MiniZinc script could even be integrated into existing tooling (Python integration seems very well supported - MiniZinc Python — MiniZinc Python 0.9.0 documentation).
Over time I would plan to look into all of the above. But I’m putting this to the side for now to prioritise other stuff (so not sure when I’ll get round to it). I’m sharing this in case anyone else fancies exploring any of these ideas further. ![]()
I’d be particularly appreciative of your feedback @sat, @SvenF, @timk11, @ZackDS, @LaCosta if/when you get a chance. No worries if you’re too busy.
Thanks for reading if you got this far ![]()
5 Likes
Voted to adopt. This proposal adds another 3 nodes to subnet uzr34, given that this subnet currently has 31 nodes and the target number of nodes was recently increased to 34 in the updated target topology. As seen in the proposal (which I verified using the DRE tool), the overall effect of these additions is to increase the log average Nakamoto coefficient while still keeping the number of nodes per node provider, data centre, data centre owner and country within the limits specified in the target topology.
2 Likes