Most of the comments resulting from the discussions of the WG meeting yesterday have been incorporated into the text. There are a few notes with a FIX label that still need to be addressed by the group. One of them is the best practices on encoding of types not part of the Value type in elements of this type.
This draft is very close to the final version with only minor changes expected.
The current draft is expected to be very close to the final version of the standard. See my comment above for the diff to the version discussed in the recent meeting. We don’t expect any more material changes to how things work.
Hi Mr. Sommer, I appreciate this. In fact, I’m implementing it now. One more question tho, I know this shouldnt be asked, but pls humor me. We should implement our own mint and burn function, yes?
Good and valid question! Yes, indeed, please implement those as you see fit! Mint and burn are not part of the standard to not constrain it unnecessarily.
B.t.w., it would be great to hear back from you if you run into hard- or / awkward-to-implement parts of the standard.
P.S.: Great to see that you are implementing this standard!
The discussion on how to model further types like bool in metadata has not been resolved yet in the current draft. Here’s a post to trigger a discussion on it.
For reference, here is the Value type:
type Value = variant {
Blob : blob;
Text : text;
Nat : nat;
Int : int;
Array : vec Value;
Map : vec record { text; Value };
};
Proposed addition
Recommendations for Metadata Encoding
There is currently no standard available on how to encode metadata. Metadata attributes are expressed as elements of the Value type, which is a recursively-defined data structure which allows for computing hashes in a well-defined way, used for linking the transactions in the transaction log.
However, the Value type is a minimal type not covering all basic data types that metadata may need to express. A prominent example for this is the bool type. This recommendation expresses how to encode additional types. This encoding does not contain the type information but only the encoded value and thus requires the scheme to be know in order to decode the type.
bool
A bool is encoded as an element of type Value by encoding it is the nat variant of Value with 0 representing false and 1 representing true.
\Proposed addition
Questions
Is this what we have in mind?
Do we agree that we do not want the type be contained in the encoding? Otherwise something like encoding it as blob might be more appropriate, e.g. putting the following into a blob: ”1:bool” for a bool with value 1. This would be an encoding that allows to regenerate the schema from the encoding.
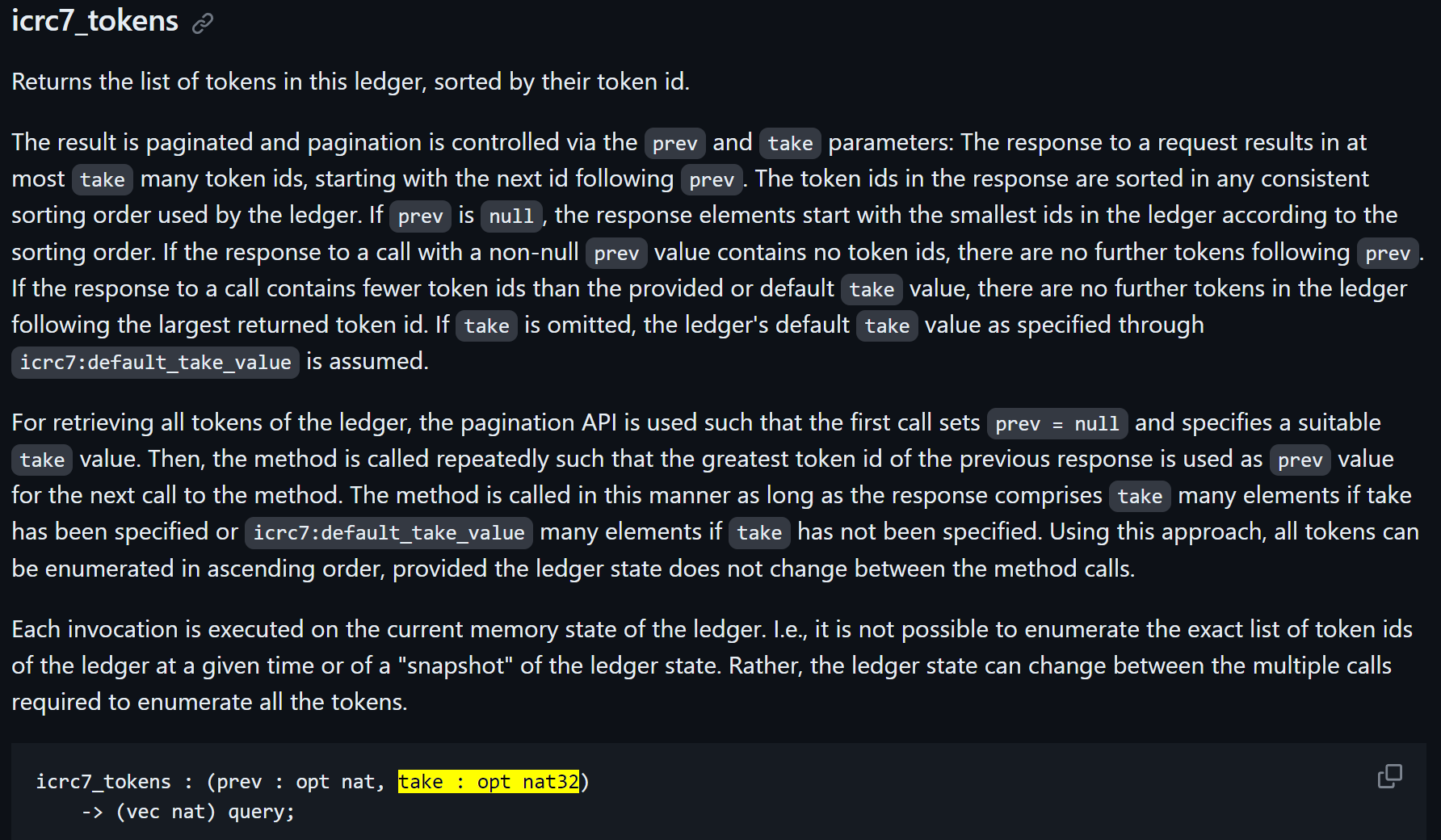
hi, regarding this… Instead of prev, I would like to suggest to use from.
Using prev means that it will not be included in the result (the word not is already a negative here),
while from can mean that it might be included in the result.
Not only that, we should also pass the optional next token_id as next variable so the next request can use its from parameter.
for example (simplified for brevity)
tokens: [(id, metadata)] = [
(1, larry),
(2, jake),
(3, arwald),
(4, hugh),
(5, ruru),
(6, raj),
(7, puddi)
];
public shared query func icrc7_tokens(from: Nat, take: Nat32) : async {
tokens: [Nat], next: ?Nat
} {
// implementation skipped
};
-- // let's test
icrc7_tokens(0, 5);
// result = { tokens = [1, 2, 3, 4, 5]; next = ?6; };
// the `next` (6) can be use now
icrc7_tokens(6, 5);
// result = { tokens = [6, 7]; next = null; };
what do you guys think?
also, why is the take have to be Nat32 as per highlighted?
I found something awkward.
The approval: ApprovalInfo object is singular but if the caller specified the created_at_time, the TooOld and CreatedInFuture will be placed in every elements in the result array? doesnt look pretty to me that’s all
I think it will be better if we separate the approval: ApprovalInfo errors and the tokens’ errors array.
Maybe something like this?
public shared func icrc7_approve_tokens(
token_ids: [Nat],
approval: ApprovalInfo,
) : async {
#RequestRejected : { // for if the approval object is invalid
#TooOld; #CreatedInFuture; #SelfApproval; #BeyondBatchMaxLimit;
};
#Result : [{ #Ok; #Unauthorized; #NotExist; }]
} {
// check caller and approval.spender
// check created_at_time
// check max_approvals_per_token
// throw #RequestRejected error
// begin forlooping each token and validating
// populate the result array with errors if any
};
… or maybe I didnt correctly understand the approval flow?
The intended semantics of the prev parameter is that values larger than it are returned, the prev value itself excluded. The reason is that this is the required meaning when enumerating all elements of the ledger.
Using prev for your example:
You make a first call icrc7_tokens(0, 5); and get back { tokens = [1, 2, 3, 4, 5]; next = ?6; }; now you know that 5 is the largest element in this response.
Next, you make the call icrc7_tokens(5, 5);, where the first 5 is exactly the largest response of the previous call. Then you get back { tokens = [6, 7]; next = null; }. The fact that the number of returned values is smaller than the take parameter means there are no further values.
The proposed approach just uses the largest value from the previous request as prev and the response starts with elements larger than this, but it not included as we already have received it. So the prev approach seems to work as intended. It was the simplest approach we could think of. Disclaimer: We have not implemented it yet, so maybe your point is based on working with it.
What is not clear to me: Do you think that there is an issue with the semantics of prev or do you think the from / next approach is just nicer in general or nicer to work with?
No strong feeling about it. What do you think would make more sense? nat64 or nat? nat32 is a little bit constraining, but 4 billion elements is a lot for a single ledger. But I also thought about this same issue some time back, but then did not make a change proposal.
Do you think we should rediscuss this in the group?
I also thought that this would be nice, but remembering the discussions on ICRC-3, where this type is defined, the goal was to have this rather minimal. And I think that it is fixed now. My preference would also be to have it in this type.
More generally: Value is a low-level type used for the implementation of the tx log, so maybe using something higher-level for the API would have been a good idea.
ICRC-1 uses an even simplified and less general variation of Value for its metadata.
i see. i was just wondering if there’s really a reason behind it. again, if possible, i would just use nat because it’s just prettier and I wont have to use Nat32.toNat(take) to remove the yellow squiggly lines when i compare it with a nat in vscode . Again, no big deal…
I am still wondering what is the use case of approvals in ledgers. Had reached a need for it for a moment, but then forgot what it was. I think we should also provide some info on why these approvals are needed and their use cases in both fungible and nonfungible.
If Dfinity allows me to run all the workgroup videos through AI transcription + summary, that may provide some insights. I’ve watched only one, but I’m not sure if they are all public.
That would be the same for the transfer function, right?
The problem you point out is essentially that the TooOld and CreatedInFuture errors are for the whole request and not related to individual tokens. The cleanest way to handle this would be a “top-level” error being returned for the request. This would, however, make the API overall more complex.
One way to handle it would be analogous to what is proposed for ICRC-4, which is also what you propose.
Here, there is a top-level error and then an error per token. This is conceptually nicer, but also complicates the API. I think the reason to go for this was to have a simpler API. But now that you bring it up when implementing, there may be a point in changing.
The group should definitely have another discussion on this one. It would effect essentially all the update APIs as we would want to be consistent. Also consistency with ICRC-4 might be a good point.
So my current strategy is to store the metadata as Candy (0.3.0alpha is at https://github.com/icdevs/candy_library/tree/0.3.0-alpha/src). This lets me store a class at the top level which gives me the ability to mark properties as immutable or not(which is pretty important with these blockchain things).
When the candy comes out and must be converted to a Value I’m using this function(if we think nat is better than blob I can easily change it).
For fungies they make the deposit flow a lot cleaner…I don’t actually take your tokens until I provide the service I have promised.
For NFTs they exist to allow a user to give a marketplace the right to transfer the NFT for them upon a sale. It keeps the user from having to transfer ownership to the marketplace, and the way we’ve implemented it allows the user to authorize multiple marketplaces.
Of course, I prefer putting the marketplace in the NFT like we’ve done with Origyn, but I get the thinking of why we put it in.
These are legit use cases, but they can also be achieved with external contracts. Having it inside the ledger probably speeds things up, but having it outside can provide other security guarantees, modularity, and reusability. Thanks for explaining
Edit: Imo, If someone provides a ready-install audited WASM like the icrc1 ledger by Dfinity, all will be good and devs won’t need to worry about making complex ledgers to get to building apps.
Just wondering whether we would want a method icrc7_update_metadata to update metadata of an NFT. This would allow for dynamic NFT use cases, which would set the IC apart from other chains. When not having it here, we would need another standard to handle this.